



公開日:
生成AIを活用したボイスボットや会話型エージェントの開発において、「音声」だけでなく「テキスト」を同時に画面に表示したいというニーズは非常に一般的です。聴覚情報の補助や、会話履歴の可視化は、ユーザー体験(UX)を大きく向上させます。
Agora が提供するConversational AI Engine(以下、Convo AI)は、LLMとリアルタイム音声通話技術を統合したソリューションです。本記事では、Convo AI向けに提供されているToolkitを活用し、Webクライアント上で会話の文字起こし(Live Transcript)を表示する実装方法を解説します。

※ 本記事は、以下 Agora 公式ドキュメントを基に、編集・構成しました。
・https://docs.agora.io/en/conversational-ai/overview/product-overview
・https://docs.agora.io/en/conversational-ai/develop/transcripts
・https://docs.agora.io/en/conversational-ai/develop/event-notifications
・https://www.agora.io/en/products/conversational-ai-engine/
尚、本記事で紹介している Agora 製品の仕様、API、およびGitHub リポジトリ上のサンプルコードは、執筆時点(2025 年 12 月)のものです。今後のアップデートにより、予告なく変更される場合があります。最新の実装については、必ず公式ドキュメントやリポジトリをご確認ください。
Agora Convo AI Engineとは
Agora Convo AI Engineは、ユーザーの音声をリアルタイムでAIエージェントと対話させるためのオーケストレーション・プラットフォームです。
開発者は、OpenAIやGemini、Claudeといった任意の LLMや、Azure、ElevenLabsなどのTTS(音声合成)モデルを自由に組み合わせることができます。Agora の超低遅延ネットワーク(SD-RTN™)を利用することで、AI エージェントの応答遅延を最小限に抑え、人間同士のような自然な会話を実現します。
通常の処理パイプライン(Chained Model)
Convo AIの基本的な処理フローは「Chained Model(連鎖モデル)」と呼ばれ、以下の順序で処理されます。
- ASR (Automatic Speech Recognition): ユーザーの音声をテキストに変換
- LLM (Large Language Model): テキストに応じた応答を生成
- TTS (Text-to-Speech): 応答テキストを音声に変換
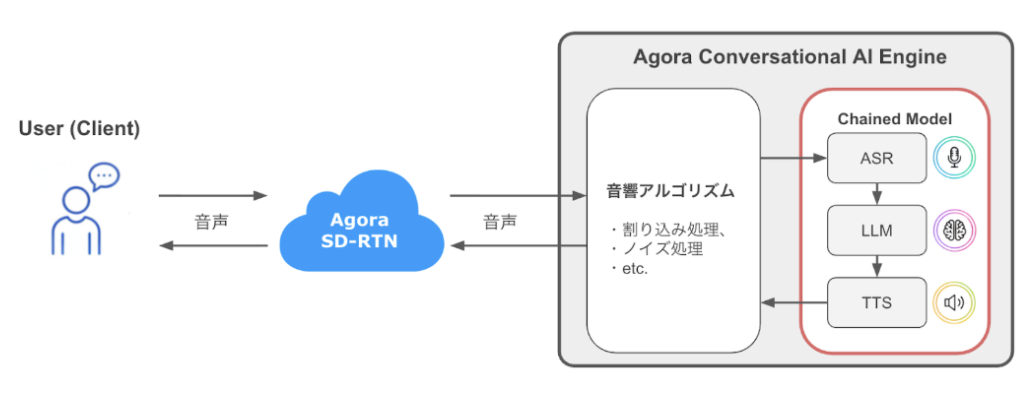
この音声処理パイプラインに加え、ユーザーとAIエージェントとの対話を文字起こしし、クライアントへ配信する仕組みが「Live Transcript」です。
Live Transcriptの仕組みとToolkit
Live Transcriptのデータフロー
Convo AI Engineでは、Live Transcriptのデータとして以下を取り扱います:
- Agent Transcript: エージェントの発話内容(リアルタイム更新および確定結果)
- User Transcript: ユーザーの発話内容
- Transcript Status: 処理中、完了、中断などのステータス
音声データは Video SDK (RTC)経由でストリーム配信されるのに対し、Live Transcriptデータの場合は、Convo AI Engine からは Signaling SDK または VideoSDK のデータストリームとして配信されます。
Conversational AI Engine Toolkitとは
Agora社では、Signaling SDKでのLive Transcript配信を推奨アプローチとしており、そのためのツールが Conversational AI Engine Toolkitとして用意されています。
このToolkitは、Video SDKとSignaling SDKの機能をカプセル化したラッパーライブラリであり、開発者は複雑なシグナリング制御を意識せずに、以下の機能を容易に実装できます。
- Live Transcript(文字起こし)の表示
- エージェントのステータス監視(Thinking, Speakingなど)
- エージェントへの割り込み処理
- etc.
Agoraの公式ドキュメントでは、上記機能をはじめとする実装例を複数紹介しています。
興味のある方は、以下リンク先の一覧からそれぞれドキュメントをご覧ください:
実装の前提条件
Toolkit は iOS / Android / Webそれぞれのプラットフォームで利用可能です。本記事では Web 版を用いた実装方法を解説します。
Web アプリケーションで Live Transcriptを実装するには、以下の準備が必要です。
- RESTful APIの利用準備: Convo AI Engine は RESTful APIを用いてAIエージェントの設定・制御を行います。RESTful API の利用手順、基本操作については、こちらの記事をご覧ください。
- Webアプリケーションの実装: Video SDK のクイックスタートのような、通話機能を有するWebアプリケーションをベースとする必要があります。
- Agora Signaling SDKの実装: Live Transcriptデータの受信時に使用します。Signalingサービスのご利用に関する相談は、ブイキューブにお問い合わせください。
- インスタンス管理の準備: Toolkitは、Video SDK や Signaling SDKのインスタンス自体の初期化や認証(トークン管理)は行いません。これらはアプリ側で管理し、アクティブなインスタンスを Toolkit に渡す必要があります。
実装手順 (Web / JavaScript)
Web クライアントでの具体的な実装手順を解説します。
プロジェクト構成と Toolkit の準備
実装に入る前に、ディレクトリ構成と Toolkit の配置について確認します。 Agora が提供する Toolkitは、npm パッケージではなくソースコードとして提供されています。公式リポジトリからフォルダごとコピーして、プロジェクトに配置する必要があります。
Toolkit の導入手順:
- GitHub の Conversational-AI-Demo リポジトリにアクセスします。
- Web/Scenes/VoiceAgent/src/conversational-ai-api と Web/Scenes/VoiceAgent/src/lib フォルダを探します。
- これらのフォルダをダウンロードし、自分のプロジェクトのsrc 配下に配置します。
ディレクトリ構成イメージ:
my-convo-ai-project/
├── index.html
├── package.json
├── ...
└── src/
├── main.js
├── conversational-ai-api/
│ ├── index.ts
│ ├── type.ts
│ └── utils/
│ ├── index.ts
│ ├── events.ts
│ └── sub-render.ts
└── lib/
├── logger.ts
└── utils.ts
補足解説:
公式ドキュメントには記載がありませんが、現状のバージョンでは lib/logger.ts と lib/util.tsが内部的に参照されているため、これらも配置する必要があります(将来的なバージョンアップでディレクトリ構成や依存関係が整理される可能性があります)。
必要なnpmパッケージのインストール:
npm i agora-rtc-sdk-ng agora-rtm-sdk clsx jszip lodash tailwind-merge
Step 1: HTMLの準備
文字起こしテキストを表示するためのコンテナ( index.html )を用意します。
<div id="transcript">の中に、受信した文字起こしデータを表示していく形式をとります。

Step 2: 各SDKのインスタンス作成
src/main.jsの冒頭で、Agora Video SDK (RTC) と Signaling SDK (RTM)のクライアントを作成します。
Toolkitはこれら2つのクライアントのラッパーとして機能するため、先にインスタンスを用意します。
import AgoraRTC from "agora-rtc-sdk-ng";
import AgoraRTM from 'agora-rtm-sdk';
import { ConversationalAIAPI } from "./conversational-ai-api";
import { ETranscriptHelperMode, EConversationalAIAPIEvents } from "./conversational-ai-api/type";
const { RTM } = AgoraRTM;
const appId = "YOUR_APP_ID";
// テスト用トークン (本番環境ではサーバーから取得した値を設定します)
const rtcToken = null;
const rtmToken = null;
const channel = "test_channel";
const uid = 12345; // 固定の UID
let RTCClient = null;
let SignalingClient = null;
let conversationalAIAPI = null;
function initializeClients() {
// 1. 音声とテキストの同期用設定
AgoraRTC.setParameter("ENABLE_AUDIO_PTS_METADATA", true);
// 2. Video SDK (音声通話用)
RTCClient = AgoraRTC.createClient({ mode: "rtc", codec: "vp8" });
// 3. Signaling SDK (Transcript 受信用)
try {
SignalingClient = new RTM(appId, "" + uid);
} catch (error) {
console.error("[Signaling] Error:", error);
}
}
コード解説:
- AgoraRTC.setParameter("ENABLE_AUDIO_PTS_METADATA", true); : この設定は、Toolkit が「AI エージェントの音声」と「文字起こしテキスト」のタイミングを正確に同期させて表示するために必要となります。VideoSDK クライアントの作成前に、この設定を有効にしてください。
Step 3: Toolkit の初期化とイベントハンドラの設定
Toolkitを初期化し、文字起こしデータを受信するための設定を行います。
Toolkit は Signaling 経由で受信したパケットを解析し、オブジェクト配列に変換してから TRANSCRIPT_UPDATEDイベントを発火します。
function setupConversationalAI() {
console.log("[AI API] Initializing instance...");
// Toolkit に RTC と Signaling のインスタンスを渡して初期化
ConversationalAIAPI.init({
rtcEngine: RTCClient,
rtmEngine: SignalingClient,
renderMode: ETranscriptHelperMode.TEXT,
enableLog: true
});
// シングルトンインスタンスを取得
conversationalAIAPI = ConversationalAIAPI.getInstance();
// --- イベントリスナーの登録 ---
// 文字起こしデータの受信イベント
// Signaling 経由で新しいテキストが届くたびに、このコールバックが実行されます
conversationalAIAPI.on(
EConversationalAIAPIEvents.TRANSCRIPT_UPDATED,
(transcription) => {
updateTranscriptUI(transcription);
}
);
// エージェントの状態変化イベント (オプション)
// エージェントが「思考中」「発話中」などの状態になったことを検知できます
conversationalAIAPI.on(
EConversationalAIAPIEvents.AGENT_STATE_CHANGED,
(agentId, state) => {
console.log(`[Agent State] ${state.state}`);
}
);
}
// UI への描画処理コールバック
function updateTranscriptUI(transcription) {
const transcriptDiv = document.getElementById('transcript');
transcriptDiv.innerHTML = '';
// 配列の最後尾(最新)から 3 件を取得して表示
const recentMessages = transcription.slice(-3);
recentMessages.forEach(item => {
const p = document.createElement('p');
// item.uid: 発話者のID (User または Agent)
// item.text: 解析済みの文字起こしテキスト
p.textContent = `${item.uid}: ${item.text}`;
transcriptDiv.appendChild(p);
});
}
コード解説:
- TRANSCRIPT_UPDATED: 文字起こしデータが更新されたときに発火するイベントです。
- コールバック引数の transcription: 最新の会話内容が含まれる配列です。主に、以下の情報が含まれています。
- uid: 発話者のIDです。0はユーザー自身のIDを、それ以外はAIエージェントIDを表します。
- turn_id: 会話のターン(やり取りの順番)を示すIDです。ユーザーとAIの一往復の対話が、一つの turn_id として管理されます。
- text: 認識された音声を文字起こししたテキストデータです。
- status: 文字起こししたテキストデータの確定状態 (確定中、確定完了、など) を示します。
- metadata: その他の付加情報を含むオブジェクトデータです。
- Convo AIから送られてくるTranscriptデータは、ユーザーおよび AI エージェントのこれまでの会話履歴の配列データとなります。ここでは、直近の会話を表示するために、新しいものから3件取得して表示するようにしています。
Step 4: 音声再生用リスナーの設定 (RTC)
Toolkitはテキストデータのみを扱います。エージェントの音声を聞くためには、RTC クライアント側で音声トラックをSubscribeし、再生を行う必要があります。
function setupRTCEventListeners() {
RTCClient.removeAllListeners(); // リスナーの重複登録を防止
// リモートユーザー(エージェント)が参加してきた時のイベント
RTCClient.on("user-published", async (user, mediaType) => {
// 音声データを Subscribe
await RTCClient.subscribe(user, mediaType);
// 音声トラックであれば再生する
if (mediaType === "audio") {
user.audioTrack.play();
}
});
}
Step 5: 接続シーケンス (Join)
各機能を実行し、通話を開始します。今回は音声通話のみを行うため、マイク音声(Audio Track)のみを生成して送信します。Signalingのログインと、チャンネルへのSubscribeが完了してから、Toolkitの subscribeMessageを呼び出します。Toolkit の subscribeMessage を呼び出さないと、文字起こしデータ更新のイベント ( TRANSCRIPT_UPDATED ) を検知できません。
async function joinChannel() {
if (!RTCClient || !SignalingClient) return;
try {
// 1. リスナー設定 (毎回リセットして再登録)
setupRTCEventListeners();
setupConversationalAI();
// 2. Signaling へのログイン
await SignalingClient.login({ token: rtmToken });
// 3. RTC (Video SDK) への参加
await RTCClient.join(appId, channel, rtcToken, uid);
// 4. マイクの有効化
// ※ 映像は送らないので、Audio Track のみを作成します
const localAudio = await AgoraRTC.createMicrophoneAudioTrack();
// Audio Track のみ配信
await RTCClient.publish([localAudio]);
// 5. Signaling チャンネルの Subscribe
await SignalingClient.subscribe(channel);
// 6. Toolkit の Subscribe 開始
// ここで文字起こしの受信処理が開始されます
console.log("[AI API] Starting subscription...");
conversationalAIAPI.subscribeMessage(channel);
} catch (error) {
console.error("[Error] Join failed:", error);
}
}
Step 6: リソースの解放 (Leave)
通話終了時は、メモリリークや次回の接続エラーを防ぐため、Toolkitを明示的に破棄します。
async function leaveChannel() {
// 1. Toolkit の終了処理
if (conversationalAIAPI) {
conversationalAIAPI.unsubscribe(); // Subscribe 停止
conversationalAIAPI.destroy(); // 内部キャッシュとリスナーの破棄
conversationalAIAPI = null;
}
// 2. RTC/Signaling のからの退出
await RTCClient.leave();
if (SignalingClient) {
await SignalingClient.logout();
}
console.log("Left channel and cleaned up resources.");
}
// ページ読み込み時に初期化を実行
window.onload = () => {
initializeClients();
document.getElementById("join").onclick = joinChannel;
document.getElementById("leave").onclick = leaveChannel;
};
Step 7:動作確認
実装ができたら、実際に動かして確認してみましょう。
1. Web アプリの起動
まずはクライアント側を待機状態にします。
- Web アプリを実装した開発サーバーを起動し、ブラウザで index.html にアクセスします。
- 画面上の「Join」ボタンをクリックします。
- ブラウザからマイクの使用許可を求められるの場合は「許可」を選択します。
2. AI エージェントの起動(RESTful API)
次に、Webアプリと同じチャンネルにAIエージェントを参加させます。
Convo AIのRESTful APIである start APIを実行しますが、Live Transcript を有効にするためのパラメーターをリクエストに含める必要があります。
|
パラメータ |
説明 |
必須 |
|
advanced_features.enable_rtm: true |
Signalingサービスを開始します |
はい |
|
parameters.data_channel: "rtm" |
Live Transcriptデータを Signaling で転送するようにします |
はい |
|
parameters.enable_metrics: true |
エージェントのパフォーマンスデータの収集を有効にします |
任意 |
|
parameters.enable_error_message: true |
エージェントのエラーイベントのレポートを有効にします |
任意 |
{
...
"channel_name": "test_channel", // Webアプリで指定したチャンネル名と一致させる
"advanced_features": {
"enable_rtm": true // [必須]
},
"parameters": {
"data_channel": "rtm", // [必須]
// 以下はオプションですが、デバッグに便利です
"enable_metrics": true,
"enable_error_message": true
}
// その他、LLM や TTS の設定など
...
}
3. 会話と文字起こしの確認
API リクエストが成功し、AI エージェントがチャンネルに参加したのを確認できたら、マイクに向かって「こんにちは」と話しかけてみてください。
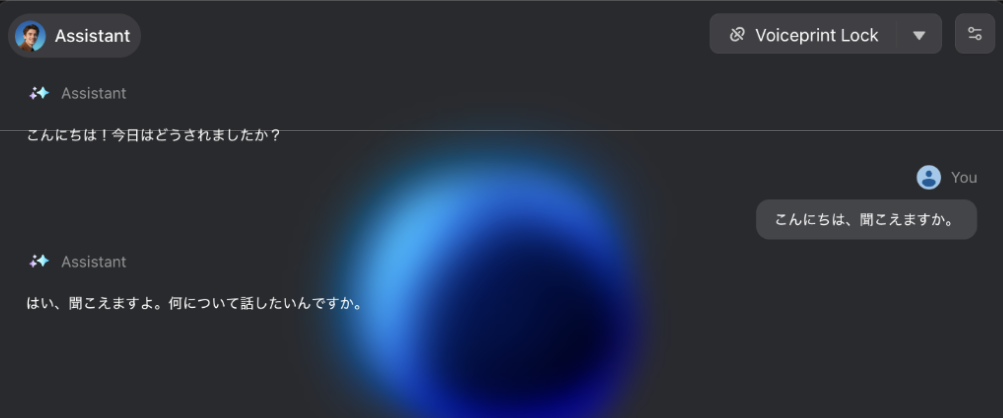
以下は、実行デモのキャプチャ画像です。
※ 各行の先頭の数字は発言者の ID を表します。ここでは、0 がユーザーで、13579 が AI エージェントとなります。

まとめ
本記事では、Agora Convo AI Engine と Toolkit を活用した Live Transcriptの実装について解説しました。 Toolkitは、Signaling SDK の複雑なメッセージ処理やパケット解析を隠蔽し、シンプルな APIを提供します。これにより、開発者は TRANSCRIPT_UPDATED などのイベントを処理するだけで、スムーズにアプリへ機能を組み込むことができます。
「音声」に加えて「テキスト」による視覚的なフィードバックを提供することは、アクセシビリティの向上だけでなく、ユーザーがAIとの対話により深く没入できる重要な要素となります。 本記事が、実装の参考になれば幸いです。

執筆者ブイキューブ
